前言
应用场景:自动部署系统发布后发现问题,需要回滚到某一个commit,再重新发布
原理:先将本地分支退回到某个commit,删除远程分支,再重新push本地分支
操作步骤:
1 |
|
Tips:获取
the_commit_id使用git log,然后找到需要回滚到的那个提交的id hash值。
应用场景:自动部署系统发布后发现问题,需要回滚到某一个commit,再重新发布
原理:先将本地分支退回到某个commit,删除远程分支,再重新push本地分支
操作步骤:
1 |
|
Tips:获取
the_commit_id使用git log,然后找到需要回滚到的那个提交的id hash值。
前段时间业务上有一个需求,这个需求需要查询数据库,由于单表数据比较大,导致出现超过5s的慢查询。随后,为了快速修复慢查询对整个系统带来的影响,将查询的数据源通过简单粗暴的修改配置切换到从库上。此后,增加了memcached来缓存一些case下的查询数据,但是对从库配置实现方式,并没有去调整。
最近,有其他业务的数据查询也需要切换到从库上,因此对上述简单的配置实现进行了思考。
动态数据源,其实就是根据我们的代码实现和配置来选择不同的数据源进行sql操作。一般地,我们会把读操作移到从库中,从而减轻主库的压力,也就是所谓的读写分离。
当然,对于一些使用数据库中间件来完成读写分离,而不需要业务层来做。这种方式,在大互联网公司中大量使用,比如360基于mysql-proxy的Atlas,阿里的DRDS(基于淘宝之前开源的TDDL)以及网易的分布式数据库中间件DDB等等。
对于一些未使用部署数据库中间件的公司,简单的方法就是在代码里面使用AOP方式通过对每个DAO层sql请求进行配置,来完成自定义的动态数据源。
Spring提供了一个抽象类AbstractRoutingDataSource,该类可以让开发人员快速实现数据源路由完成根据不同请求使用不同数据源的需求。
AbstractRoutingDataSource抽象类,继承关系如下图:
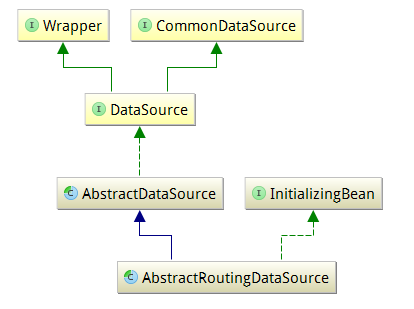
Notes: 抽象类最终继承
javax.sql.DataSource类,该数据源类提供的一些接口就是我们最终需要实现的。
DataSource接口主要提供了两个方法给开发者实现,因此实现动态数据源,我们只需要把这两个方法的实现,在调用数据库查询的时候,告知执行上下文,运行环境拿到对应的数据库连接,就可以连接到对应的数据库进行查询更新等操作。
1 |
|
倒序索引是一种索引数据结构,该索引存储单词(或者其他内容)到它们位于文件,档案或者数据库等位置之间的映射关系。这个通常被用来实现全文搜素服务,但是这要求在搜索之前这些文档的相关倒序索引就必须建立好。
因此,我们想要事业Redis来作为背后的存储系统来实现全文搜索服务。
我们的实现,将为每一个单词,准备一个set集合,这些集合包含对应的文档的ID。为了允许快速搜索,我们将在开始之前为所有的文档建立索引。
搜索服务本身先分割请求为各个单词,然后获取每个单词匹配的集合set的交集,最后就可以返回包含所有我们搜索的单词的文档ID集。
首先,让我们假设我们有一百个允许我们搜索的文档或者网页,因此需要对它们建立倒序索引。为了建立索引,我们必须分割文本为分开的单词(分词操作),在此过程中,可能需要排除stop word以及长度小于3的单词。使用Ruby脚本,如下所示:
1 |
|
所以,我们将过滤掉这些已经被加入到索引的单词,然后为我们的文档生成唯一的ID。此外,我们仍然需要完成上面的索引方法:
想要借助 Redis的PUB/SUB功能,使用node.js和Socket.io实现一个轻量级的实时聊天系统。
由于Redis 天生就支持发布订阅(pub/sub)模式,所以我们可以很容易就使用Node.js 和 Socket.IO来快速创建一个实时的聊天系统。
发布订阅模式,其实就是接收者订阅某种特定模式的消息(比如,发送到某个指定channel的消息),而发送者发送一个消息到消息云上。当一个消息到达云上的时候,订阅了这一种类的客户端就会获得消息。这中发布订阅模式,然后就可以允许发送者和接收客户端在不知道彼此的情况下,亲密结对交流。而他们仅仅需要以一种既定的模式发送消息和接收匹配类型的消息即可。
Redis直接支持pub/sub模式,意味着其可以让接收客户端订阅指定的匹配消息频道channel,以及发布消息到一个给定的频道channel。这意味着,我们可以很简单地创建像chat:cars的聊车频道;或者像chat:sausage这种关于食物的谈话。此外,频道channel的命名跟Redis 的keySpace无关,所以不用担心会存在某些冲突情况。下面给出,Redis支持的一些命令:
* PUBLISH:发布消息到指定的频道;
* SUBSCRIBE:订阅一个指定频道的消息;
* UNSUBSCRIBE:取消订阅一个指定频道;
* PSUBSCRIBE:订阅一个满足给定模式的频道集;
* PUNSUBSCRIBE:取消订阅满足指定模式的频道集。
拥有上面这些知识,为在应用程序逻辑部分之间的终端用户或者流消息实现一个聊天和统计系统,其实还是很琐碎的。pub/sub甚至可以被用来作为一个内建的强壮阻塞队列系统。接下来看看,如何去实现这么一个消息聊天系统吧。
在服务端,Node.js 和 Socket.IO将来实现网络层,然后Redis将作为一个在客户端之间递交消息的pub/sub功能的实现。在客户端,我们使用jQuery来处理消息,然后发送数据到服务器上。
Guava是Google开源出来的Java常用工具集库,包括集合|缓存|并发|字符串|IO操作等在Java开发过程中经常需要去实现的工具类.
显然,对于这种十分常见的需求,Guava提供了自己的工具类实现.GuavaCache 提供了一般我们使用缓存所需要的几乎所有的功能,主要有:
自动将entry节点加载进缓存结构中;
当缓存的数据已经超过预先设置的最大值时,使用LRU算法移除一些数据;
具备根据entry节点上次被访问或者写入的时间来计算过期机制;
缓存的key被封装在WeakReference引用内;
缓存的value被封装在WeakReference或者SoftReference引用内;
移除entry节点,可以触发监听器通知事件;
统计缓存使用过程中命中率/异常率/未命中率等数据。
此外,Guava Cache其核心数据结构大体上和ConcurrentHashMap一致,具体细节上会有些区别。功能上,ConcurrentMap会一直保存所有添加的元素,直到显式地移除.相对地,Guava Cache为了限制内存占用,通常都设定为自动回收元素.在某些场景下,尽管它不回收元素,也是很有用的,因为它会自动加载缓存.
存储分析或者其他基于时间序列的数据,对于传统的存储系统(比如RDBMS)来说,是有一点挑战的。可能你想要对输入流量的速率进行限制(要求快速和高并发更新)或者简单地追踪网站访问者(或者其他更复杂的度量指标),然后以图表的形式画出来。
虽然当前在其他系统中,有很多的方式存储这类数据;但是,Redis是一个非常优秀的候选者,由于它强大的数据结构。
Redis 理念上非常适合存储这类数据,以及跟踪某种特定的事件。具有原子性的,并且非常快的(O(1)时间复杂度)HINCR和HINCRBY命令,结合快速数据查找,使得它非常适合这类场景。
在Redis中一种好的高效内存存储这类数据的方式是使用hash来存储统计值,使用HINCRBY增加它们,然后使用HGET和HMGET来获取这些数据。查找位于top位置的元素通过SORT命令也是很容易做到的。
说明:算法背景和解法来自https://github.com/ketao1989/The-Art-Of-Programming-By-July.git,如有版权问题,请留言告知!
最近看博客,发现一些有趣的算法,很久没接触,都不清楚了。这里,把上述的github中一些算法用java实现。
给定一个字符串,要求把字符串前面的若干个字符移动到字符串的尾部,如把字符串“abcddg”前面的2个字符’a’和’b’移动到字符串的尾部,使得原字符串变成字符串“cdcgab”。请写一个函数完成此功能,要求对长度为n的字符串操作的时间复杂度为 O(n),空间复杂度为 O(1)。
1 |
|
插播广告:ubuntu系统的sublime text 3 中文无法输入,需要修复一些so库。参考:http://jingyan.baidu.com/article/f3ad7d0ff8731609c3345b3b.html
虽然java开发已经快两年了,但是对于java内部一些小的技巧和坑还是会有些不了解。这里记录下。
前段时间看书,顺带提到说Integer.valueOf( )会导致死锁问题很是惊讶。于是,查看了JDK源码,果然如此。
JDK代码对把-128 到127 之间的整数转换成Integer的时候,并不会new一个新的Integer对象,而是从 内部的IntegerCache中直接获取已经创建好的对象(第一次调用时会创建这个IntegerCache)。
由于内部
IntegerCache共用,所以在不同的地方对同一个数值调用valueOf获取cache中同一个对象,这样很可能会导致死锁。此外,关于整数范围可以使用VM初始设置(-XX:AutoBoxCacheMax=,但是不能比127小)
valueOf方法实际上就是调用IntegerCache获取对应下标的对象,而IntegerCache实际上就是一个Integer对象数组。关于IntegerCache实现如下所示:
1 |
|
之所以会导致死锁,主要原因是因为当两个线程不断的调用valueOf时,比如一个为
Integer a=Integer.valueOf(10) + Integer.valueOf(20),另外一个线程调用Integer b= Integer.valueOf(20) +Integer.valueOf(10),while中不停的调用,就可能出现死锁异常。
最近线上遇到一个很奇怪的现象,就是一个dubbo 服务被注册到了好几个group下面,并且这些group都是我们应用中,通过dubbo:registry来配置的。但是,显然这不是我们应用所期待的结果,因此,首先,我们需要修复这个问题;其次,我们需要找出原因。
首先看配置:
1 |
|
从上面的配置可以看到,我们实际上是有dubbo:registry,并且在其中也设置了group属性。
今天项目发布,上线上跟日志的时候,发现一些死锁信息的出现,查询了一下,发现日志里面虽然死锁出现很少,但是都是同一个代码sql语句产生的,如下图所示:

并且,一天产生死锁31次。
从DBA那边拿到了对应死锁的Mysql日志信息:
1 | ------------------------ |
Note: 数据库中,
CH01313318和CH01313320序列号是连着的两个记录。
之所以需要分析这个问题,主要原因是,这边代码并没有涉及到在一个事务内部sql操作导致死锁等常见的情况。