前言
该文档是提供给期望使用 Zookeeper协作服务功能的开发者创建分布式应用的。文档内部包含了一些概念上和实践应用上的资料信息。
在指南的前四节主要讨论了 Zookeeper 各方面的概念。这些东西对于理解 Zookeeper如何工作以及如何去使用 Zookeeper 是非常必要的。它虽然没有包含源代码,但是它是假设读者对于分布式计算相关的问题是很熟悉的。它们主要如下介绍:
后面四节主要提供了一些实践编程相关的资料。主要是:
文档最后的附录部分包含了一些有用的,Zookeeper 相关的链接。
虽然,该指南中的很多资料在其他一些独立的文章博客中都已经存在了,但是对于开始第一个 Zookeeper 应用的你来说,还是最后阅读完Zookeeper 数据模型 和 Zookeeper 操作指南。
Zookeeper 数据模型
Zookeeper 有一个分级的命名空间,类似于一个分布式的文件系统。唯一不同的是命名空间中每个节点可以有对应的数据关联它,就像孩子一样。这一点类似于文件系统中允许一个文件也可以成为目录一样。到节点的路径常常表示成正则的,绝对的,斜线分隔的路径;它们没有相对的引用。在路径上使用的任何编码需要满足以下限制:
null字符不可以成为路径名字的一部分。- 由于显示的问题,如下字符不能使用:
\u0001-\u001F和\u007F-\u009F. - 下面字符同样不被允许:
\ud800-\u0F8FF和\uFFF0-\uFFFF. .字符可以作为路径名字中某块名的一部分,但是.和..不能单独作为路径的一块,因为在 Zookeeper 中不允许相对路径。因此,如下是非法的:/a/b/./c或者/a/b/../c.zookeeper字符串保留。
ZNodes
ZooKeeper 树上的每一个节点都称之为znode。Znodes 维护了一个包含数据变化和acl变化版本号的状态结构体。这个结构体也包含时间戳。因此,版本号和时间戳一起确保Zookeeper验证缓存和协调更新。每一次znode的数据变化,版本号也会对应增长。例如,当一个客户端检索数据时,它也会获得该数据的版本号,然后当一个客户端执行更新或者删除时,它必须提供对应变化的znode的数据版本。如果它提供的版本不能够匹配到实际的数据版本时,更新将会失败。
Note:
在分布式应用工程中,node常常被看做一个主机,一台服务器,一组中的一个成员等等。在Zookeeper文档中,znodes称为数据节点;Servers则是标记为Zookeeper服务的机器;quorum peers是标记为一个集群的所有服务器;client是任何使用Zookeeper服务的机器或者进程。
Znodes是开发者访问的最主要的实体。它们有一些值得去关注的特征:
Watches
客户端可以在 znodes 上设置监听。znode 的改变将会触发监听器,然后清理监听。当一个监听器被触发时,Zookeeper 会发送对应客户端一个通知。更新的信息可以参考 Zookeeper 监听。
数据访问
保存在一个命名空间里的每个节点上的数据都可以被原子的读和写。读,获取对应znode上所有的数据字节;然后一个写,替换所有的数据。每个节点上的ACL(访问控制列表)可以限制who can do what。
Zookeeper 不是被设计用来作为一个通用的数据库或者大对象的存储。相反,它是用来管理协调数据的。这个数据来源于配置,状态信息,集结地点等形式中。一般,协调的数据相对来说是很小的:几千字节计算。Zookeeper 客户端和服务器实现的时候会确保znode的数据小于1M,但是通常数据会比那个小得多。操作相对大的数据将会导致一些操作会花费更对的时间,从而一些操作的延迟性,这主要是因为一些额外的时间需要被用来在网络上移动更多的数据,存储起来。如果一定需要大数据的存储,通常的处理方式是将数据存储在大容量存储系统上,比如 NFS 或者 HDFS ,然后再Zookeeper里保持存储位置的指针。
短暂节点
Zookeeper 也有短暂节点的概念。在会话创建时,znode存活;当会话结束时,znode删除。由于这个特性,所以其不允许有孩子。
顺序节点-唯一命名
当创建一个znode时,你也可以请求Zookeeper在路径的末尾增加一个单调递增的计算器。这个计算器对父节点来说是唯一的。计算器有一个%010d格式化–表示10个数字0补全。比如:<path>0000000001。Notes:计数器用来保存下一个顺序数字是一个有符号整形,由父节点保存,当增长到2147483647将会溢出。
Zookeeper 中的 Time
Zookeeper 追踪 time的多种方式如下:
Zxid
Zookeeper状态的每次改变,在zxid(ZooKeeper Transaction Id)里都会获取到一个时间戳。这意味着在ZooKeeper中所有都变化都是有序的。每次改变都将会有一个zxid,如果 zxid1 小于 zxid2,则 zxid1 一定在 zxid2 之前发生。版本号
一个节点的每次改变都会导致对应节点的其中一个版本号递增。节点对应的三个版本号是:version(znode 数据改变对应的编号);cversion(znode 的孩子改变对应的编号);aversion(znode 的ACL改变对应的编号)。Ticks
当使用多服务器的 ZooKeeper 时,服务器使用ticks来定义事件的时间,比如,状态上传,会话超时,连接超时等。tick 时间只能间接地表示最小的会话超时(每tick时间内2次);如果一个客户端请求的会话超时小于最小的会话超时,则服务器将会告诉客户端它请求的会话超时实际上是最小的会话超时。真实时间
ZooKeeper 不使用真实时间或者时钟时间,即使在所有我们期望把时间戳放入znode创建和修改的状态结构体里面。
ZooKeeper 状态结构体
ZooKeeper 里每个 znode 的状态结构体都包括下面这些字段:
- czxid
导致znode被创建的zxid。 - mzxid
对应znode最后一次改变的zxid。 - ctime
当该znode创建开始的毫秒数。 - mtime
当该znode最后一次更改开始的毫秒数。 - version
znode数据改变的编号。 - cversion
- aversion
- ephemeralOwner
如果该znode是临时节点,则为该节点owner的 会话id;如果不是临时节点,则为0。 - dataLength
znode 数据字段的长度。 - numChildren
znode对应孩子的个数。
Zookeeper 会话
ZooKeeper 客户端通过绑定的编程语言创建一个 handle从而和ZooKeeper服务建立会话。一旦创建完成,handle开始处在 CONNECTING 状态,然后客户端将会和ZooKeeper服务中某个服务器连接上,然后其会切换到 CONNECTED状态。在通常的操作过程中,会处在这两张状态中的一种。如果发生了一个不可恢复的错误,比如会话过期或者认证失败,再或者如果应用显示地关闭 handle,则该 handle 将会转变为 CLOSE 状态。
下面的图展示了一个 ZooKeeper 客户端可能的状态流转情形:
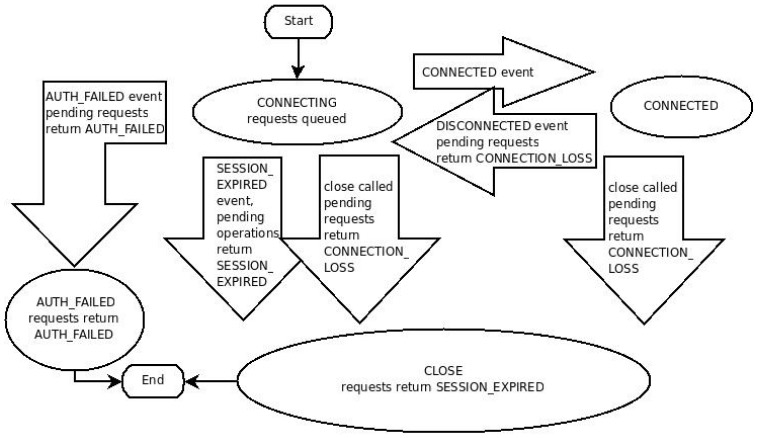
为了创建一个客户端会话,应用代码必须提供一个连接字符串,包含一个以逗号分隔的 host:pair列表, 每个host:pair 对应的是一台 ZooKeeper服务器(比如,”127.0.0.1:4545” 或者 “127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002”)。ZooKeeper 客户端会挑选任务的服务器,然后尝试去连接它。如果这个连接失败,或者这个客户端因为任何原因导致和这个服务器断开连接,客户端都将会自动尝试列表中的下一台服务器,知道一个连接被(重新)建立起来。
3.2.0 新特性:一个可选择的”chroot”后缀也可能会添加到连接字符串中。和linux中的chroot命令相似,运行客户端的所有命令中的路径都是相对这个root来确定的。比如我们如果使用:”127.0.0.1:4545/app/a” 或者 “127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002/app/a”,则客户端将会以”/app/a” 为root,然后所有路径都是相对这个root而言的–例如,我们获取 “/foo/bar” 下面的文件,则实际上将会在 “app/a/foo/bar” 下面执行。这个特性对于多租户环境下是很有用的,这样每个用户在 ZooKeeper服务上其root都可以不同。因此,对于每个用户如果编码他们的应用中以”/“为root情况下,重复使用ZooKeeper服务将非常简单。
当一个客户端获取到ZooKeeper服务的一个handle,ZooKeeper 创建一个ZooKeeper 会话,以 64位数字表示。如果客户端连接到一台不同的 ZooKeeper服务器,它将会发送一个会话id作为连接握手的一部分。作为一个安全手段,服务器为该会话id创建一个任何ZooKeeper服务器都可以验证的password。当客户端建立完会话之后,password 将会和会话id一起发送给客户端。当客户端需要和新的服务器重新建立连接时,则发送该password 和 会话id。
ZooKeeper 客户端库调用创建一个ZooKeeper会话时,其中有一个参数是毫秒数的会话超时。客户端发送一个请求超时,服务器将响应从客户端获取的超时。当前的时候要求超时时间最小为 2 个 tckTime,并且最大为 20 个 tickTime。ZooKeeper 客户端API 运行访问协商的超时。
当一个客户端(会话)从ZK服务集群里分隔开,它将会开始搜素我们在创建会话时候指定的服务器列表。最后,当客户端和至少服务器中的一台重新建立连接后,会话将会要么转化为 connected状态(如果会话重连接在超时值之内),要么转化为expired状态(如果重连在会话超时之后)。为断开连接的客户端创建一个新的会话对象是不明智的。ZK 客户端库将会为你处理重连。在实践中,我们在客户端库中会有一些启发式的算法构建来处理像”羊群效应”等事情。只有在收到会话过期通过时,才会去创建一个新的会话。
会话过期由ZooKeeper集群自己管理,而不是客户端。当ZK客户端和集群建立会话时,其提供一个超时值。集群使用这个值来决定客户端会话是否超时。当集群没有在超时时间内收到返回,则发送会话过期。在会话过期的时候,集群将会删除该会话拥有的所有的临时节点,然后立即通知监听该变化的所有连接状态的客户端。在这个时间点,超时会话的客户端仍然和集群断开连接,在重新和集群建立连接之前,它将不会收到会话超时的通知。客户端将会一直带着断开连接的状态,知道TCP连接被重新建立起来,然后 超时会话的watcher将会接收到”会话超时”的通知。
一个超时的会话状态流转的过程示例:
- connected:会话建立连接,客户端和集群处于通信中。
- 客户端从集群中分割开…
- disconnected:客户端丢失和集群之间的连接
- … 时间过去了,在 超时区间之后,集群过期了会话,客户端由于和集群断开了所以看不到任何东西。
- … 时间进行走着,客户端恢复了和集群的网络层连接、
- expired:最终,客户端重新连接上集群,然后被通知过期。
ZooKeeper 建立会话调用的另一个蚕食是默认的 watcher。当在客户端上的状态发送变更,watcher 将会被通知到。例如,如果一个客户端丢失了和服务器之间的连接,则客户端将会收到通知,或者如果客户端会话过期了。watcher 应该认为初始状态是 断开连接的。在一个新连接的case里面,发送给 watcher 的第一个通知就是会话连接事件。
会话通过客户端发送请求保持alive。如果会话空闲了会话超时时间段时,客户端将会发送 PING请求来保持会话alive。PING请求不仅允许 ZooKeeper服务器知道 客户端仍然活跃,也允许客户端通过连接验证 ZooKeeper服务器仍然活跃。PING的时间很充足,从而确保有在检测到死连接,然后重新连接到新的server的操作有足够的时间。
一旦一个到服务器的连接成功的建立了,客户端 lib 有两个基本的case 导致 连接丢失,当执行一个同步或者异步操作,然后出现如下情况:
- 在一个不再活跃/有效的会话上调用一个操作。
- 当ZooKeeper客户端挂起一个操作时,断开和服务器之间的连接。
3.2.0 新特性–SessionMovedException:这是一个内部的异常。这个异常一般发生在一个会话和不同的服务器重新建立连接后接收到请求的时候。正常导致这个错误的原因是一个哭护短发生一个请求给一个服务器,但是网络包延迟,所以客户端超时,然后和新的服务器建立间接。当延迟的包被第一台服务器收到时,老的服务器检测到会话已经被移开,然后关闭客户端连接。客户端正常下不会看着这个错误,因为他不会从老的连接中读数据。出现这种情况的一个条件是当两个客户端尝试使用 password 和 会话id 重新建立相同的连接,其中一个客户端将重新建立连接,第二个客户端将会断开连接。
更新服务器列表:我们允许客户端通过提供一组新的逗号分隔的host:port对列表来更新连接字符串。这个函数调用一个基于概率的负载均衡算法导致客户端断开和当前host的连接,从而达到服务器列表中连接的平均数。万一当前客户端连接的host不在新的列表中,这个调用将会导致连接被丢弃。另外,决定服务器数量的增加或者减少以及多少。
例如:如果前面的连接字符串包含 3 host,然后现在列表包含这 3 个 host和 2 个新加的 host,40%的客户端原来对应的连接将会迁移到新的hosts中的一个来确保均衡负载。这个方案将会导致客户端丢弃他的连接,然后0.4的概率连接到其他2台机器,在这种情况下,导致客户端随机选择连接 2 个新的host中的一台。
另一个例子–假设我们有5 台host,现在我们更新服务器列表移走 2 台host,然后客户端连接剩下 3 台host的依然连接,然后 移除的2台 host上的连接将被移动到剩下 3 台host的其中一台。如果连接丢弃,客户端移动到指定的模式,其可以选择一个新的服务器去根据概率算法连接服务器,而不是 RR。
在第一个例子中,每个客户端决定以0.4的概率来断开连接,但是一旦做完决定,它将尝试随机连接到一个新的服务器,仅仅在不能连接到新的服务器中的任何一台时,它才会尝试连接老的服务器。在找到一个服务器,或者尝试列表中所有的服务器,仍然连接失败的时候,客户端回退到正常的操作模式(从概率模式回到轮询RR模式),即从连接字符串中选择任意的服务器,然后尝试连接它。如果失败,它将以RR模式尝试不同随机服务器。
Zookeeper 监听
在 ZooKeeper 里所有的读操作(getData(),getChildren()和 exists())都可以将设置一个 watch 作为附加功能。ZooKeeper 对 watch的定义是:一个监听事件是一次性的 trigger,当监听的数据发送变化的时候,发送给设置监听的客户端们。对于这个定义,有三个关键点:
One-time trigger
当监听数据发送变化的时候,一个监听事件将会发送给客户端。例如,一个客户端使用getData("/znode1", true),然后/znode1的数据发送变化或者删除,客户端将会获得一个对应/znode1的监听事件。但是,如果/znode1再次改变,就不会再有监听事件发送出去,除非客户端通过另一个读操作来设置监听watchSent to client
这意味着一个正发送给客户端的事件,可能在发送修改操作的客户端完成操作返回成功 code 之前不会到达客户端。监听事件是异步发送给监听客户端的。ZooKeeper 提供一个有序的保证:一个客户端永远只有在看到一个watch事件之后才会看到这个watch对应的改变。网络延迟或者其他原因可能导致不同的客户端看到watch和更新返回code的时间不同。其关键之处在于不同客户端看到的所有事情都是有一致性的顺序的。The data for which the watch was set
这指的是节点改变的不同方式。你可以认为 ZooKeeper 维护 watch的两个列表:数据watch 和 孩子watch。getData()和exists()设置数据watch;getChildren()设置child监听。此外,你也可以认为 watch 可以根据数据返回的类型来设置。getData()和exists()返回节点数据的信息,然而getChildren()返回 孩子列表。因此,setData()将触发节点的数据watch 设置。一个成功的create()将会触发znode的数据watch 以及 父节点的child watch。一个成功的delete()将会触发节点的数据watch和child watch(因为将不会再有children了)。
watch 由与对应client连接的ZooKeeper服务器负责维护。因此,这可以使得 watch 可以轻量级地设置,维护和分发。当一个客户端连接到一个新的server,watch将会出现会话时间。当和server断开连接后,将不会收到watch。当一个客户端重新连接,任务先前注册的watch将会被重新注册,然后当需要的时候触发。一般情况下,这都是显示地发生的。有一个case就是一个watch可能被丢失:一个人还未创建的znode的 existence watch 将会被丢失,如果这个znode 创建,然后当断开连接的时候又被删除了。
watch 语义
我们可以通过读ZooKeeper的三种状态来设置 watch:exists, getData, 和
getChildren。下面的列表展示了一个watch 触发和调用激活的方式:
- Created event:
通过 exist调用激活。 - Deleted event:
通过调用 exists, getData, 和 getChildren 激活 - Changed event:
通过调用 exists, getData 激活。 - Child event:
通过调用 getChildren 激活。
watch 移除
我们可以调用 removeWatches 方法移除在 znode 注册的 watch。一个客户端可以本地移除watch操作,即使没有连接ZooKeeper服务器,只是本地设置标识为true。下面的列表详细说明了在成功移除watch 之后会触发什么事件:
- Child Remove event:
在调用getChildren的时候添加 watcher。 - Data Remove event:
在调用 exists 或者 getData 的时候添加 watcher。
关于 watch 需要记住的事情
- Watches 是一次性触发器。如果你获取了一个 watch 事件,然后你还想在未来更改的时候也获得通知,则你必须要设置另外的watch。
- 由于watch是一次性的触发器,并且在获取时间和发送新的请求去获取watch 这段之间的延迟,所看到的发生在 ZooKeeper Znode 上的所有改变都是不可信的。需要准备好处理在获取事件和设置watch之间znode改变多次的case。
- 一个watch对象,或者 function/context对,对于给定的通知只会被触发一次。例如,如果一个相同的watch对象被一个
exists 或者 getData文件file调用操作注册,然后这个文件file被删除了,这个watch对象将和这个文件file的删除通知一起,仅仅被调用一次。 - 当你从服务器上断开连接,你将不能获得任何watch 直到连接被重新建立起来。基于这个原因,会话事件将被发生给所有突出的watch处理器。使用会话事件会进入一个安全模式:你将不能接收事件指导断开连接,所以你的处理处理这种模式下需要谨慎。